


我们谈“世界模型”时,经常会把它想成一个宏大名词:仿佛需要先造出一个能完整复制现实的数字孪生,才配叫世界模型。但在工程语境里,它更像一种能力组合:系统能把观测压缩成状态,把状态推进到未来,再把未来反推到可执行的动作。它不必全知全能,却必须在足够多的情境里“算得对、跑得稳、改得快”。
过去两年,这条路线突然变得具体了:模型开始擅长长链条推理与工具调用;多模态把抽象符号重新绑回到真实感知;机器人政策开始从“单任务特训”走向“通用技能库”;硬件平台把推理的瓶颈从算力搬到能耗、内存与带宽。世界模型不再只是研究论文里的结构,而正在变成产业链共同对齐的一套目标函数。
1. 最新模型进步:从“生成答案”到“生成过程”
如果把 2023 年以前的大模型概括成“更像知识检索 + 文本补全”,那么近期的明显变化是:模型越来越像在生成一个可执行的推理过程,而不是只给出一个看似正确的结论。这个变化背后是推理时扩展(inference-time scaling)与强化学习训练范式的结合:让模型在更长的思维链里做更多“中间计算”,并通过可验证奖励把正确性向过程内推。
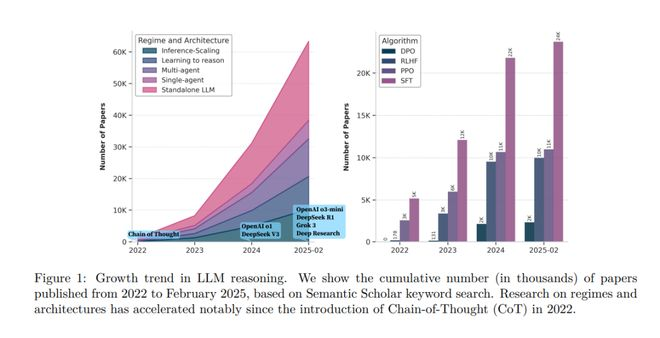
- 图注:LIM推理的增长趋势。显示了从2022年到2025年2月发表的论文累计数量(以千为单位),基于Semantic Scholar关键词搜索,自2022年引入链式思维(Chain-of-Thought,CoT)以来,关于制度和架构的研究明显加快
对世界模型而言,这一步非常关键。世界模型不是一句话能回答的问题,而是一个持续运行的系统:它要反复读取观测、维护记忆、调用工具、校验假设、更新计划。也就是说,世界模型天然是“多轮推理 + 多次行动”的形态。把大模型训练成更稳定的推理器,相当于先补齐了系统 2(慢思考、规划、反事实推演)的底座。
与此同时,模型的上下文窗口和外部记忆机制也在变得更工程化:长上下文让“持续对话”变成“持续建模”,而不是一次次重新开局;外部检索与工具接口把世界状态从“模型脑内的文本幻觉”转成“可以被重复验证的外部事实”。这为世界模型的第二个关键要素铺路:多模态与可检验的观测。
2. 多模态的重要性:世界模型必须“接地”
语言是高压缩的抽象接口,但世界不是用语言运行的。只靠文本训练出来的模型,擅长在符号空间里做一致性,却很难保证与物理因果一致。世界模型之所以必须多模态,不是为了让模型“看图识字”更强,而是为了把预测对象从“下一段文本”升级为“下一段可观测世界状态”。
机器人领域最近的 VLA(Vision-Language-Action)路线很典型:把视觉、语言与动作放到同一个建模框架里,让“看见什么、理解什么、怎么做”变成一个端到端的闭环。相关综述里普遍强调一个趋势:从分模块流水线走向统一表征与统一优化,目标是让策略能跨任务、跨物体、甚至跨不同机器人形态泛化(Vision-Language-Action survey,2025)。这种路线在能力侧看起来像“更通用的机器人”,在世界模型侧看其实是:模型必须学会把感知映射到可行动的状态空间,并在行动后用新观测修正自己。
如果说语言模型解决的是“如何在符号里做推理”,那么多模态解决的是“如何让推理对象与世界对齐”。从这一刻开始,世界模型的核心不再是文本生成的流畅度,而是对观测、行动、反馈三者之间因果结构的掌握。
3. 线性代数、分段线性区域与“高维流型”
讨论世界模型,很容易陷入直觉叙事:模型好像在脑子里画出了一张世界地图。但把它落到可计算的结构,会发现核心仍是线性代数之上的函数逼近与优化:矩阵乘法是主干,非线性激活负责把空间折叠出可用的表示。
先看数据本身。高维观测并不是“铺满”整个空间,更多时候,它们沿着受约束的子结构分布;工程里常把这种“薄的结构”叫作流型。世界模型首先要做的,是把观测压缩成更稳定、更可控的表征,让相邻关系和变化方向在表征空间里变得更清晰。
再看函数表达力。世界模型不仅要“表示世界”,还要在表征上做推进与预测,这就需要网络对空间有足够细的切分能力:在小范围内尽可能平滑可控,在全局上又能拼出复杂形状。分段线性网络提供了一个可量化切口:同一激活模式下,网络对输入是线性的;激活模式一变,就相当于切到另一块线性片段。Montúfar 等人在 2014 年从线性区域数量的角度分析了深层网络的表达复杂度(On the Number of Linear Regions of Deep Neural Networks,2014)。
最后看优化。训练做的并不是把整个空间都拟合好,而是在“数据实际出现的那一小块区域”把切分做得更合适:让流型落在更稳定、更容易推进的线性片段上,让插值、外推与长时序预测更不容易跑飞。
世界模型需要的正是这种几何能力:它要在表征里做状态推进,从 (s_t) 到 (s_{t+1}) 的动力学近似、从目标到动作序列的规划、以及从误差到策略更新的闭环。没有足够丰富且可控的表示与切分,就很难在长时序任务里保持稳定。
4. 具身智能的发展:从单点技能到“技能库 + 规划器”
具身智能的变化,首先是数据与任务分布的变化:Open X-Embodiment 这类工作试图把分散的机器人数据对齐到统一格式,并训练跨任务的 RT-X 系列模型(Open X-Embodiment,2023–2025 持续更新)。当数据分布开始跨机器人、跨场景拼在一起,策略模型就不再是“机械臂 A 的拣选器”,而更像“可迁移的动作语言模型”。
其次是架构上的分层:一类路线倾向于把高层规划(语言/符号推理)与低层控制(连续动作、反馈稳定性)分开优化,形成更像“规划器 + 技能库”的系统。VLA 综述里也经常提到双系统结构:用慢的系统负责分解任务、选择工具/技能;用快的系统负责执行与闭环纠错。这种分层与世界模型的需求高度一致:世界模型必须在高层维持一个可解释的任务结构,同时在低层保证动作的物理可行性。
更重要的是,具身智能迫使模型面对一个无法回避的事实:预测必须可检验。语言任务里,错误可以被“合理化”;但在机器人里,错误会直接表现为抓不到、撞到、摔倒。可检验性把世界模型的训练目标从“看起来对”推向“真的能用”,也推动了更真实的数据、更强的仿真、更严格的评测指标。
5. 黄仁勋的算力平台与“瓦力”式机器人:把世界模型做成产品形态
当世界模型从研究走向工程,最先被放大的是系统瓶颈:推理的吞吐、上下文的驻留、跨节点的通信、以及把传感器与动作回路跑到实时的能力。近期 NVIDIA 对“机柜级系统”的叙事,本质上是在把世界模型需要的计算形态产品化:从单卡指标转向整机柜的带宽、内存容量与可用性。
以 NVIDIA 在 CES 2026 公开的 Vera Rubin NVL72 机柜级系统为例,官方强调的是 MoE 推理 token 成本降低、NVLink 规模互联带宽以及系统级的内存/网络配置,目标指向的是“能持续推理、能持续上下文驻留、能支撑大规模 agent 的在线运行”(NVIDIA Newsroom:Rubin platform,2026)。你会发现这里的关键词与世界模型的需求对齐:世界模型不是离线训练一次就结束,而是要在运行时持续吸收观测、生成计划、调用工具,因而对上下文内存与互联有持续需求。
同一条叙事在机器人展示里更直观。Jensen Huang 在公开活动中展示过与 Disney Research、DeepMind 合作的机器人“Blue”,那种“瓦力”式的外形与互动方式,很容易让人把注意力从某个硬件参数挪开,转向一个更实际的问题:一个具身系统能不能在真实环境里持续感知、持续推理、持续行动(Euronews:Blue robot,2025)。当这种演示从单次 Demo 变成可复用的平台能力,世界模型就拥有了更明确的落地载体:把多模态预测与动作闭环做成标准件。GR00T N1:NVIDIA为具身智能打造的开源基础模型
6. 年底算力和电力费用暴增的隐含逻辑:电力与内存成为世界模型的真实边界
把世界模型当成“模型能力”会误判它的节奏;把它当成“系统能力”才能看清它的约束。算力确实在暴增,但并不等于“问题消失”,更像是瓶颈在迁移:从训练算力迁移到推理能耗,从参数规模迁移到上下文驻留,从 FLOPs 迁移到内存带宽与供应链。
狗血的事前阵子想给自己的开发机加内存,才发现内存价格暴涨,本来计划一步到位把容量拉满,结果发现同样规格的条子在短时间内涨价明显;你会下意识地开始算账:是先上容量,还是先换更快的盘、先把显卡升级,或者干脆把预算留给下一代。它看起来只是装机的小纠结,但背后是同一个规律:当工作负载变“吃内存”,价格和供给就会先让你感到边界。
电力已经是最硬的边界之一。IEA 在关于 AI 与能源的分析中给出数据中心用电的量级与增长速度:2024 年全球数据中心用电约 415 TWh(约占全球用电 1.5%),到 2030 年在基准情景下可能接近翻倍至约 945 TWh,并指出增长主要集中在美国与中国等区域(IEA:Energy demand from AI,2024/2025)。当推理成为常态、agent 成为工作流的一部分、世界模型成为在线系统,电力就会从“成本优化项”变成“部署硬约束”:配电、制冷、选址,直接决定能跑多大规模、能跑多高利用率。
内存则是第二个硬边界。世界模型需要长上下文与多路传感器缓存,需要为推理提供足够带宽与容量,这会把 HBM 与高端 DRAM 变成系统级关键材料。TrendForce 的行业报道指出,AI 相关内存需求正在抬升并挤压供给,甚至出现对 2026 年 HBM3E 价格上调的预期与产能优先级调整(TrendForce:HBM3E 2026 price hike,2025;AI consumes DRAM capacity,2025)。当“算力”被理解成 GPU 数量时,人们往往忽略内存;但当系统跑到机柜级、跑到在线推理,内存就会以非常朴素的方式出现:带宽不够就是吞吐上不去,供给不稳就是扩容做不动。
这也解释了为什么硬件平台越来越强调“上下文内存”“机柜互联”“系统可靠性”:世界模型的价值在运行时被释放,而运行时的瓶颈正逐步由能源与内存定义。
7. 世界模型什么时候真的实现
世界模型不会以“某个模型发布日”作为分水岭,它更像一条供应链与工程范式共同推进的曲线:
- 推理能力变稳定:模型能在长链条里保持正确性,并能可靠调用工具。
- 多模态变标准:预测对象从文本扩展到视觉/动作/反馈,世界开始“可检验”。
- 表示几何变可控:模型能在高维空间里形成可组合、可泛化的状态表示。
- 具身系统变平台:技能库与规划器分层,数据分布从单任务转向多任务统一。
- 硬件与能源对齐:机柜级系统把瓶颈摊开,让能耗与内存成为显式约束。
真正值得兴奋的地方在于:世界模型把“智能”从对话框里带出来,把它放到可以被验证、被部署、被迭代的系统里。它会逼迫我们重新定义很多工程指标:正确率不够,需要稳定性;延迟不够,需要闭环;模型不够,需要系统;算力不够,需要电与内存。
世界模型的到来并不浪漫,但足够真实。
参考链接
- IEA:Energy demand from AI https://www.iea.org/reports/energy-and-ai/energy-demand-from-ai
- Montúfar et al. 2014:On the Number of Linear Regions of Deep Neural Networks https://arxiv.org/abs/1402.1869
- Open X-Embodiment:https://arxiv.org/abs/2310.08864
- VLA Survey:https://vla-survey.github.io/
- NVIDIA Newsroom(Rubin platform):https://nvidianews.nvidia.com/news/rubin-platform-ai-supercomputer
- TrendForce(HBM3E price hike for 2026):https://www.trendforce.com/news/2025/12/24/news-samsung-sk-hynix-reportedly-plan-20-hbm3e-price-hike-for-2026-as-nvidia-h200-asic-demand-rises/
- TrendForce(AI consumes DRAM wafer capacity in 2026):https://www.trendforce.com/news/2025/12/26/news-ai-reportedly-to-consume-20-of-global-dram-wafer-capacity-in-2026-hbm-gddr7-lead-demand/
- Euronews(Nvidia’s AI robot “Blue”):https://www.euronews.com/video/2025/03/19/nvidias-ai-robot-blue-stuns-with-live-interaction